The collaborative research between FAIR and INRIA proposes a DensePose-RCNN model for intensive human body posture improvement based on Mask-RCNN, which is suitable for human body 3D surface construction, etc., and the effect is very good. And proposed a human body COCO data set containing 50K annotation images, which will be open source.
Intensive human pose estimation refers to mapping all human pixel points in an RGB image to the 3D surface of the human body.
We introduced the DensePose-COCO dataset, a large ground-truth dataset that manually labeled the image-to-surface counterpart on an image of 50,000 COCOs.
We proposed the DensePose-RCNN architecture, a variant of Mask-RCNN that intensively returns the UV coordinates of a particular part in each human region at multiple frames per second.
DensePose-COCO data set
We use manual annotation to create a dense correspondence from a two-dimensional image to a human surface representation. If the conventional method is used, it is necessary to manipulate the indication by rotation, resulting in inefficiency. Instead, we built an annotation process that consists of two phases to efficiently collect annotations for the image-surface correspondence.
As shown below, in the first phase, we asked the labeler to delineate the area corresponding to the visible, semantically defined body part. We instruct the marker to estimate the part of the body that is covered by the garment, so for example, wearing a large skirt does not complicate the subsequent correspondence.
In the second phase, we sample the area of ​​each part with a set of roughly equidistant points and ask the annotator to map the points to the surface. To simplify this task, we unfold the surface of the body part by providing a pre-rendered view of six identical body parts and allow the user to place markers on either of them. This allows the annotator to select the most convenient viewpoint by selecting one of the six options without manually rotating the surface.
We used the SMPL model and SURREAL textures in the data collection process.
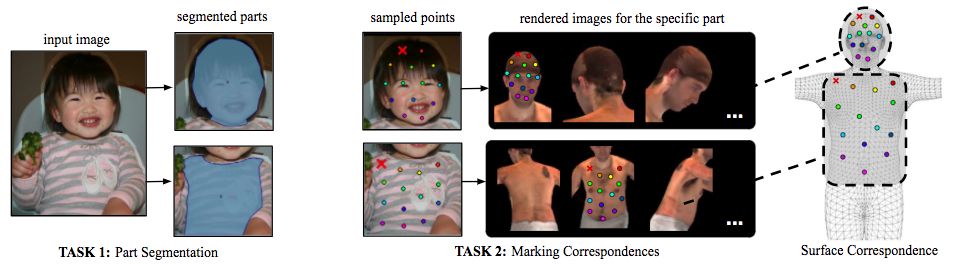
The two-stage labeling process allows us to collect highly accurate corresponding data very efficiently. The two tasks of part segmentation and correspondence annotation are basically simultaneous, which is surprising considering that the latter task is more challenging. We collected notes of 50,000 people and collected information on more than 5 million individual workers. The following is a visualization of the image annotations in our validation set: Image (left), U (medium), and V (right) are the values ​​of the collected annotation points.




DensePose-RCNN system
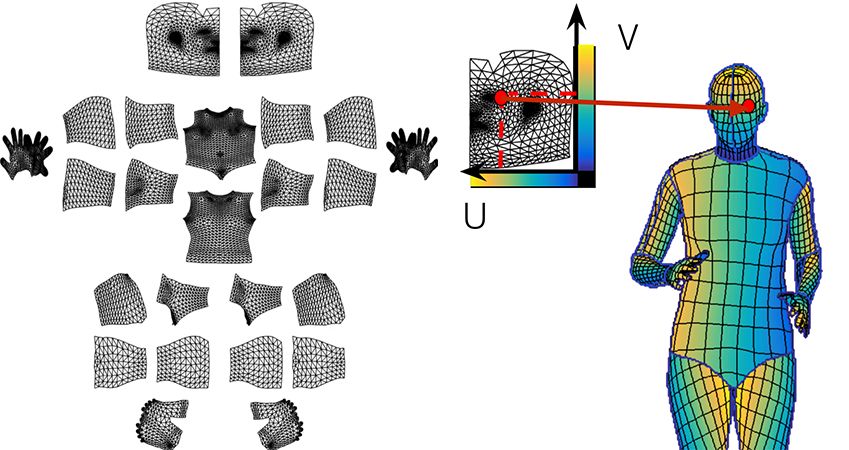
Similar to DenseReg, we look for dense correspondence by dividing the surface. For each pixel, you need to determine:
Which surface part it tends to belong to;
It corresponds to the 2D parameterized position of the part.
The right side of the figure below illustrates the division of the surface and the "correspond to points on a part".
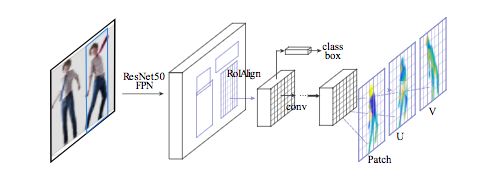
We use a Mask-RCNN structure with a feature pyramid network (FPN) and a ROI-Align pool to obtain dense part labels and coordinates within each selected area.
As shown in the following figure, we introduce a full convolutional network based on ROI-pooling for the following two tasks:
Generate classification results per pixel to select surface locations
Regress local coordinates for each part
During the reasoning process, our system uses the GTX1080 GPU to run at 25fps on a 320x240 image and 4-5fps on an 800x1100 image.
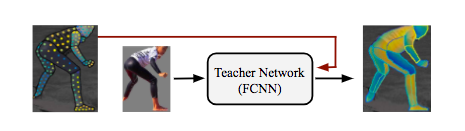
The DensePose-RCNN system can use annotation points directly as a supervisor. However, we achieved better results by "patching" the value of the supervisory signal at a location that was not originally marked. To achieve this, we use a learning-based approach that first trains a "teacher" network: a fully convolutional neural network (as shown below) that reconstructs the ground-truth value and the segmentation mask for a given image.
We use cascading strategies to further improve the performance of the system. Through cascading, we use information from related tasks, such as key point estimates and instance segmentation that have been successfully solved by the Mask-RCNN architecture. This allows us to take advantage of the synergies of task synergies and different sources of supervision.
Fork Type Terminals,Insulated Bullet Sockets Terminals,Insulated Bullet Terminals,Type Fork Insulate Terminal
Taixing Longyi Terminals Co.,Ltd. , https://www.longyiterminals.com