In the Tutorial of IJCAI2016, Microsoft Research Institute described its application of deep learning and deep neural networks to different scenarios. The first part mentioned some experiences and gains in semantic understanding. This article is the second part.
Joint compilation: Blake, Zhang Min, Chen Chun

Statistical Machine Translation (SMT) includes:
l Statistics
l Source channel model
l Translation model
l Language Model
Log-linear model
l Evaluation indicator: BLEU score (higher is better)

Phrase-Based Statistical Machine Translation (SMT) translates Chinese into English

Core issues: What model is targeted?
l For vocabulary possibilities
Language model
LM/w source
l Phrase-based machine translation Translation/recording possibilities
translation
Recording
l Binary-based machine translation
l ITG model

Example of neural network in phrase-based SMT
l Neural network as an integral part of the linear model
Translation model
The Use of Pre-Pressure Model Curl Neural Networks
Joint model FFLM and original vocabulary
l Neural Machine Translation (NMT)
Create a single, large neural network to read sentences and output translations
RNN encoding - decoding
Long-term memory
Joint learning sequence, translation
NMT Outperforms Best Results on WMT Tasks

Although the phrase translation model is simple, it solves the problem of sparse data.

Deep Semantic Similarity Model (DSSM)
l Calculate semantic similarity btw text
l DSSM for Natural Semantic Processing Tasks

DSSM for phrase translation models
l Two neural networks (one source direction and one direction)
enter
Output
l phrase translation score = vector dot product
fraction
To mitigate data sparseness, allow for complex fractional functions

N-gram language model
l Word n-gram model (eg n=3)
l Problems with long history
Scarce events: Estimates of the likelihood of unreliability

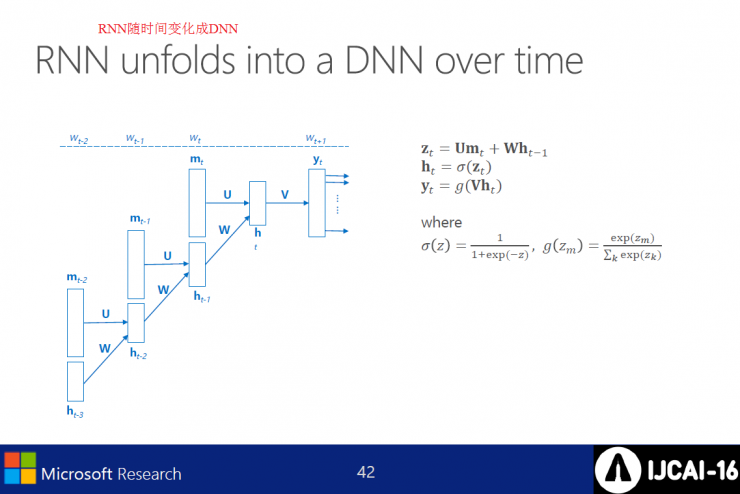

RNN LMs need to return to the beginning of the sentence, which also makes dynamic planning more difficult. In order to score a new vocabulary, the state of each decoder needs to be maintained at h, and the assumptions are merged by combining the traditional n-gram context with the best h.

Simulation S requires 3 conditions: 1. The entire source sentence or the balanced source vocabulary 2. S as a lexical sequence, vocabulary packet, or vector representation 3. How to learn the vector representation of S? The joint neural network model is based on a recursive neural network language model and a feedforward neural network model.
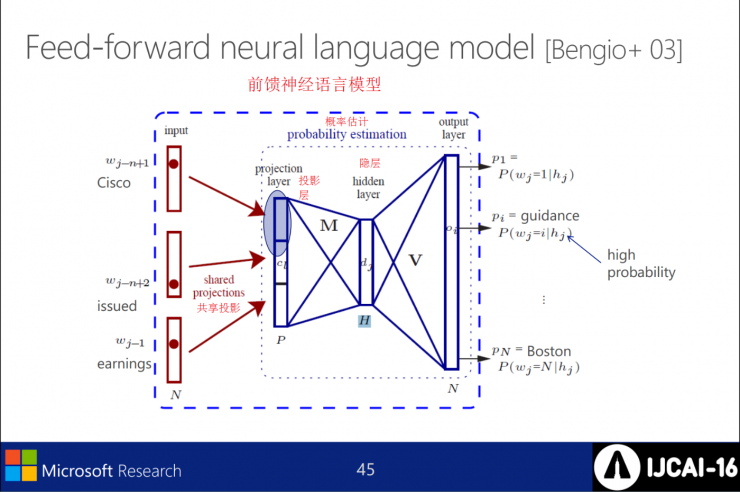
Feed forward neural language model

Extend the feedforward LM so that it contains windows surrounded by a balanced source vocabulary. If you want to align multiple source vocabularies, select the middle position; if no alignment is necessary, inherit the queue of the closest target vocabulary. At the same time use the queue to train in the text; optimize the possibility of the goal.

Neural machine translation, build a single, large NN, read sentences and enter translations. Unlike phrase-based systems, many parts model components are required. The encoder-decoder basic method is: an encoder RNN reads and encodes a source sentence into a fixed-length vector, a decoder RNN outputs a variable-length translation from an encoder vector, and finally an encoder-decoder RNNs work together to learn texts and optimize target possibilities.
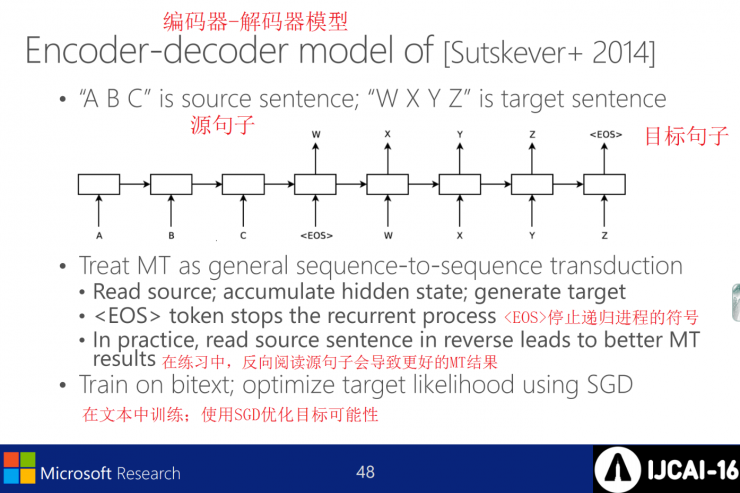
[Sutskever+2014] Encoder-Decoder Model
Treat MT as a universal sequence-to-sequence translation, reading the source; accumulating hidden states; generating targets. among them
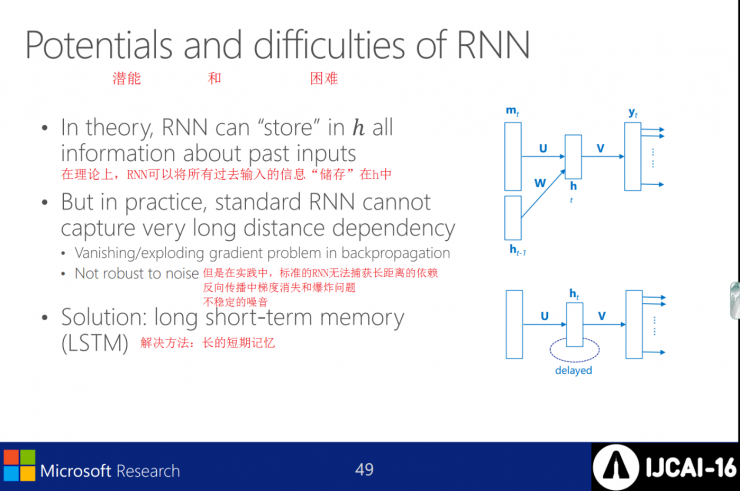
Potential and difficult
In theory, the RNN can “store†all past input information in h, but in reality the standard RNN cannot capture long-distance dependencies. The solution to the problems of gradient disappearance and explosion and unstable noise in back propagation is: long short-term memory.
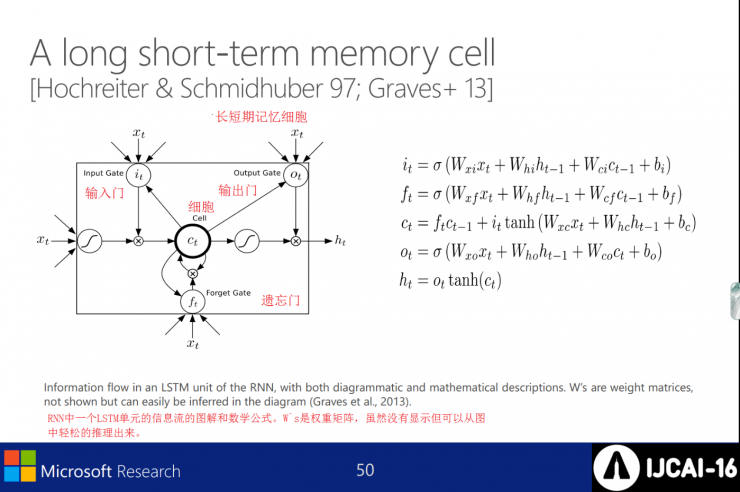
Long and short-term memory cells
Graphical and mathematical formulas for the flow of information in an LSTM cell in an RNN. W`s is a weight matrix, although it is not shown but it can be easily deduced from the graph.

Two doors of memory cells
Figure 2: Implicit activation function proposed. The update gate z decides whether the hidden state is updated with the new hidden state h. The reset gate r determines whether the previous hidden state is ignored.

Arrangement and translation of joint learning
There is a problem in the SMT encoder-decoder model: Compressing source information into a fixed-length vector makes it difficult for RNN to complicate long sentences. The attention model is: code the input sentence to the vector queue and select a subset of the vectors when decoding
It is similar to [Devlin+14].

Attention model of [Bahdanan+15]
Encoder: Two-way RNN encodes every word and text
Decoder: Finds a series of source vocabularies that are most relevant to the predicted target vocabulary, and predicts the target vocabulary based on the source vocabulary and all previously generated vocabulary-related text vectors. This translates to long-term performance close to optimal performance.

MSR`s neural dialogue engine




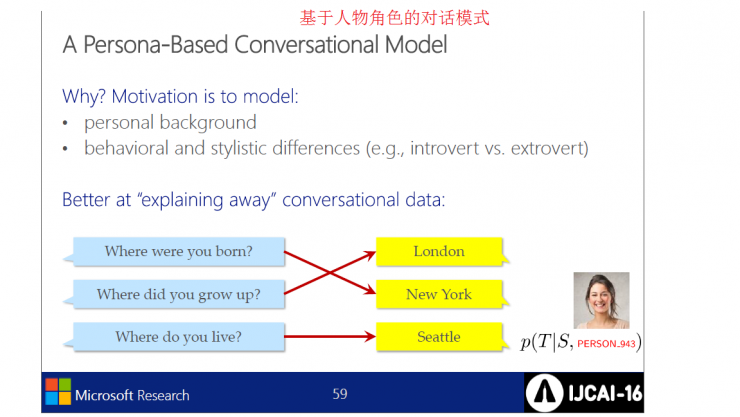
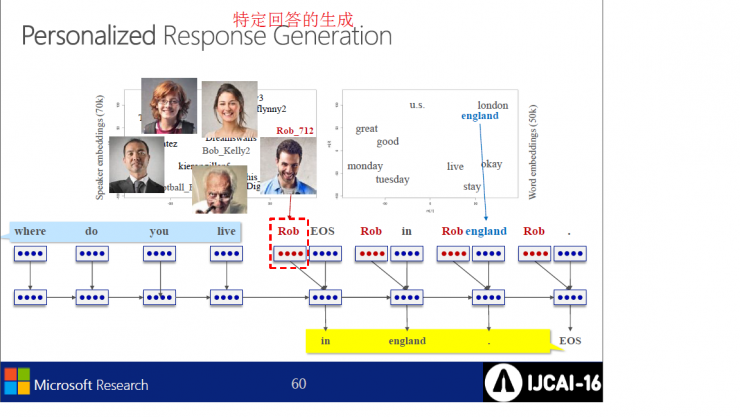




to sum up:
This section mainly introduces deep neural network examples for classifying problems, as well as the application of deep learning in statistical machine translation and dialogues. It also mentions semantic expression learning and natural language understanding.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.
Poly Dome Array For Remote Control,Poly Dome For Remote Control,Remote Control Poly Dome,Membrane Switch Poly Domes
zhejiang goldcity technology co,ltd , https://www.membrane-gc.com